개발서버 정리 1탄) 용량 비우기, 안쓰는 파일 삭제 개발서버 정리 2탄) 서버에 걸리는 부하 검사하기
1. 현재 나의 용량 확인하기
df : 디스크의 남은 용량을 확인
df -h : 보기 좋게 보여줌
du : 현재 디렉토리에서 서브디렉토리까지의 사용량을 확인
du -a : 현재 디렉토리의 사용량을 파일단위 출력
du -s : 총 사용량을 확인
du -h : 보기 좋게 바꿔줌
du -sh * : 한단계 서브디렉토리 기준으로 보여준다.
- 가장 자주 쓰이는 것들로 정리.
2. 불필요 파일 삭제
! 읽기 전에 파일 삭제할때는 항상 경로를 주는게 좋다. !
rm abc.txt
abc.txt 파일을 삭제한다.
rm *.txt
'.txt'로 끝나는 파일을 모두 삭제한다.
rm *
모든 파일을 삭제한다. (위험)
rm -r dir1/
dir1 디렉토리를 삭제한다.
디렉토리를 삭제하기 위해서는 -r 옵션을 사용해야 한다. (recursive)
rm -rf dir1/
r 옵션과 함께 f 옵션을 사용하게 되면 경고 없이 모두 강제(force)로 삭제한다.
서버에 걸리는 부하를 파악해서 해결하려면, 먼저 서버에 어떤 부하가 걸리는지 부터 알아야 한다.
우리가 확인할 수 있는 서버부하는 크게 네트워크 부하 와 서버의 성능 부하 로 분류됨.
네트워크 부하는 말 그대로, 서버에 접속하려는 사람이 폭발적으로 증가하여 트래픽이 급증한 경우의 네트워크에 걸리는 부하를 말한다.
이러한 경우 서버 앞단에서 트래픽 자체를 분산시켜주는 로드밸런서를 사용하거나 서버의 대수를 더 늘리는 방식으로 해결할 수 있음.
하지만, 애초에 우리의 서버가 서버 자체의 성능을 100% 발휘하고 있지 않다면 서버의 대수를 늘리거나 로드밸런서를 사용해도 그 효율이 매우 낮을 것이다.
따라서 로드밸런서 등으로 네트워크 부하에 대한 분산을 고려하기 전에, 서버 1대가 자신의 성능을 잘 발휘하고 있는지 부터 확인해 볼 필요가 있다.
우리는 이런 서버부하를 확인해 볼 것이다.
단일 서버의 병목 원인 조사
단일 서버에 걸리는 부하의 원인은 크게 2가지로 분류됨.
- CPU 부하
- I/O 부하
CPU 부하가 높은 경우는 서버에서 실행되고 있는 프로그램 자체의 연산량이 많은 경우나 프로그램에 오류등이 발생한 경우다.
이러한 경우에는 프로그램 오류를 제거하거나 알고리즘의 시간, 공간 복잡도를 개선하여 대응해야 한다.
I/O 부하가 높은 경우는 서버에서 실행되고 있는 프로그램의 입출력이 많거나, DB나 하드디스크 등의 저장장치로의 접근이 많아 스왑이 발생하는 경우가 대부분이다. 우리 회사의 경우 파일DB사용, 파일세션 사용, 파일 캐시사용으로 I/O부하가 높은 편이다.
이러한 경우 특정한 프로세스가 극단적으로 메모리를 소비하고 있는지 확인한 후, 프로그램 자체에 오류가 있다면 프로그램을 개선하거나 탑재된 메모리의 용량 자체가 부족한 경우 램을 추가하여 메모리를 증설하는 방법으로 대응할 수 있다.
저장장치나 하드디스크로의 입출력이 빈번하게 발생하는 경우 또한 메모리를 증설하거나, 메모리 증설로 대응할 수 없는 경우는 데이터 자체를 분산 (샤딩이나 파티셔닝) 하거나 캐시서버등을 도입하는 방안을 고려해볼 수 있다.
단일 서버에서 발생하는 부하의 원인은 이렇고, 이러한 부하를 측정해보자.
운영체제에서 프로세스를 실행하는 방식과 부하의 측정
리눅스나 윈도우 등의 운영체제 에서는, 동시에 여러 프로세스들을 처리하기 위해 아래와 같은 멀티 태스킹 방식을 사용함.
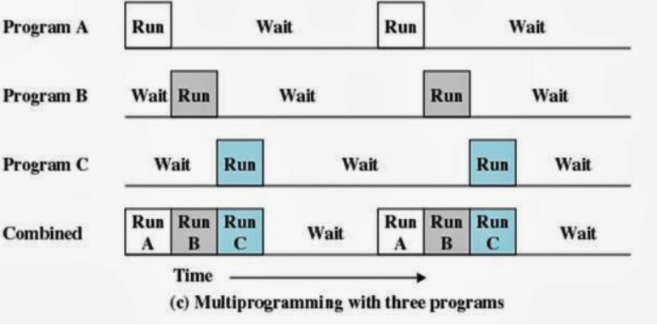
CPU나 디스크 등의 유한한 하드웨어에서 여러 프로세스들을 동시에 처리하기 위해, 매우 짧은 시간 간격으로 여러 프로세스들을 돌아가면서 처리하는 방식이다.
이러한 멀티태스킹 방식에서, 처리해야 할 프로세스가 점점 많아지면 어떻게 될까? CPU 를 사용하고 싶어 대기하고 있는 프로세스들이 점점 쌓이게 된다.
이렇게 CPU 를 사용하려고 기다리고 있는 프로세스 를 운영체제 에서는 Load average (평균 부하) 라고 정의한다.
CPU를 사용하려고 기다리고 있는 프로세스가 많을 수록, CPU는 바쁘다는 의미이고 결국 시스템에 걸리는 부하가 크다는 뜻.
리눅스에선 top 명령어에서 이러한 Load average 를 확인할 수 있다.
top 명령어로 1분, 5분, 15분 동안 몇개의 태스크가 CPU를 사용하려고 기다리고 있는 대기 상태에 있었는지 를 알 수 있습니다.
따라서 load average 가 높은 상황은 지연되는 태스크가 많다는 것을 의미합니다.
다음은 top명령어의 세부정보 항목에 대한 설명이다.
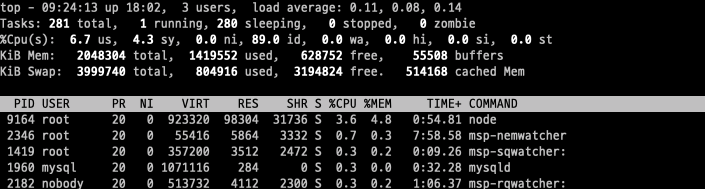
1. CPU
%us : 유저 레벨에서 사용하고 있는 CPU의 비중
%sy : 시스템 레벨에서 사용하고 있는 CPU비중
%id : 유휴 상태의 CPU 비중
%wa : 시스템이 I/O 요청을 처리하지 못한 상태에서의 CPU idle 상태인 비중
2. 세부 정보 필드별 항목
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
* PID : 프로세스 ID (PID)
* USER : 프로세스를 실행시킨 사용자 ID
* PRI : 프로세스의 우선순위 (priority)
* NI : NICE 값. 일의 nice value값이다. 마이너스를 가지는 nice value는 우선순위가 높음.
* VIRT : 가상 메모리의 사용량(SWAP+RES)
* RES : 현재 페이지가 상주하고 있는 크기(Resident Size)
* SHR : 분할된 페이지, 프로세스에 의해 사용된 메모리를 나눈 메모리의 총합.
* S : 프로세스의 상태 [ S(sleeping), R(running), W(swapped out process), Z(zombies) ]
* %CPU : 프로세스가 사용하는 CPU의 사용율
* %MEM : 프로세스가 사용하는 메모리의 사용율
* TIME+ : 프로세스 시작된 이후 경과된 총 시간
* COMMAND : 실행된 명령어
3. top 실행 후 명령어
shift + p : CPU 사용률이 높은 프로세스 순서대로 표시
shift + m : 메모리 사용률이 높은 프로세스 순서대로 표시
shift + t : 프로세스가 돌아가고 있는 시간 순서대로 표시
-a 메모리 사용량에 따라 정렬
하지만, load average 는 단순히 지연되는 태스크의 수 를 의미하며, CPU 부하가 높은지 I/O 부하가 높은지 까지는 상세하게 알 수 없다.
sar 명령어를 통한 부하의 측정
sar 명령어로 CPU 바운드한 시스템에서의 CPU 사용률을 확인해보자.

위의 결과에서 %user 는 사용자 모드에서의 CPU 사용률 을 나타내며 %system 은 시스템 모드에서의 CPU 사용률 입니다. iowait은 io사용률을 나타낸다.
개발서버가 이유없이 느려진다면 위에있는 명령어들을 이용하여 원인이 무엇인지 확인하고 해결할 수 있다!!!