배치 모니터링, Scouter로 편하고 효율적으로
들어가며
8월의 어느날 저의 페이스북 타임라인에 Scouter이라는 글 하나가 올라왔습니다.

예전 서비스에서 제니퍼라는 상용 APM을 사용하며 웹 서비스 성능 모니터링에 많은 도움이 되었던 기억이 떠올랐습니다. 이내 곧 오픈소스 APM Scouter를 제가 담당하는 모니터링 목적에 맞게 살펴보기 시작했습니다.
저는 티몬에서 정산 및 결산 업무를 담당하고 있습니다. 정산 및 매출데이터를 가공하기 위해 실시간 웹 서비스의 개발보다는 배치 위주의 개발을 많이 합니다. 따라서 Scouter를 HTTP 서비스 모니터링 보다는 배치에서 만들어지는 데이터에 대하여 모니터링을 진행해보면 좋겠다는 생각이 들었습니다.
관련하여 프로토 타입을 아래와 같이 정리했습니다.
* Scouter로 해보고 싶은 것 정리
* Scouter 설치 및 설정
* 배치서비스 NON-HTTP 서비스 추적
* 배치 작업 수행 시 특정 데이터 기준으로 Agent 스크립트 작성하여 프로파일에 반영
* 개발된 Server 플러그인으로 Agent로 생성된 프로파일링 및 성능 데이터를 Elasticsearch에 집계
Scouter로 해보고 싶은 것?
제가 담당하는 주업무인 배치의 경우, 대부분 새벽시간에 이루어지기 때문에 실시간 모니터링 보다는 나중에 확인할 수 있는 형태가 필요했습니다. 배치 작업에 대한 데이터 흐름 및 성능에 대한 일부 데이터를 프로파일링 한 후 집계를 해보겠습니다.
1. Scouter가 제공하는 클라이언트에서 과거 이력에 대한 데이터가 남기 때문에 확인할 수 있지만 디스크 용량의 80%까지만 보관 가능하며 오래된 데이터부터 지움
2. 배치 수행 시 사용된 데이터를 스냅샷 용도의 데이터로 적재 후 운영관리 용도로 조회
정산 및 결산 데이터를 생성하기 위해서는 다양한 배치들이 존재하고 각각의 배치들은 의존관계를 가집니다. 보통 복잡한 계산에 의해 생성되지만, 샘플링을 위해 아래와 같은 간략한 흐름을 가진 정산 배치가 있다고 해봅시다.
1. 판매데이터를 조회한다.
2. 조회된 판매데이터를 가지고 정산계산식을 통하여
3. 최종 정산데이터를 만들어낸다.
위의 흐름을 가진 배치는 스프링 배치로 개발되며 배치 프로세스는 아래와 같습니다.
[배치 프로세스]
1. 대용량의 데이터 처리를 위하여 쓰레드 할당 (Spring Batch Partitioner)
- 각각의 쓰레드에서 reader-processor-writer을 가지는 구조
2. reader에서 판매데이터를 읽어 들이고
3. processor에서 판매데이터를 가지고 정산계산식을 통하여 정산데이터를 만들고
4. writer에서 정산데이터를 특정저장소에 적재
다음은 위의 배치 프로세스에서 Scouter를 통하여 모니터링/집계를 해보고 싶은 항목입니다.
[Scouter로 모니터링/집계 해보고 싶은 항목]
1. reader, processor, writer의 각 메소드에서 프로파일링한 데이터
- 특정상품ID의 판매데이터
- 계산식에 사용된 데이터
- 정산데이터
2. Scouter의 성능데이터인 XLog 항목들
- 서비스 클래스
- 메소드
- 수행시간
- 에러정보
- ..
Scouter 설치 및 설정
Socuter의 공식페이지에 Scouter에 대한 내용이 잘 정리되있으며 설치에 대한 것은 아래 페이지를 참고바랍니다.
- https://github.com/scouter-project/scouter/blob/master/README_kr.md
1. 설치하기
다운로드 페이지에서 Server / Agent / Client를 다운로드 받습니다. 클라이언트의 경우, 본인이 사용하는 PC의 플랫폼에 따라 다운받면 되며 저는 윈도우 64bit 버전을 다운받았습니다.
1) Downoad Page
2) Server Download
3) Agent Download
4) Client Download
2. Server 설정 및 실행
- scouter/server/conf/scouter.conf
- scouter/server/startup.bat실행
3. Agent 설정 및 실행
- scouter/agent.host/conf/scouter.conf
- scouter/agent.host/host.bat실행
배치 NON-HTTP서비스 추적
배치의 경우 HTTP서비스가 아니기 때문에 WAS가 아닌 실행 서버에서 서비스를 추적해야 합니다.
서비스 추적은 NON-HTTP-Service-Trace_kr.md 문서를 참고하세요.
정산관련배치 3개의 reader, preocessor, writer의 메소드를 서비스 패턴으로 설정합니다.
- scouter/agent.host/conf/scouter.conf 에 아래내용 추가
이제 배치를 실행하여 해당 서비스 패턴으로 등록된 서비스들을 Scouter 클라이언트로 모니터링 하겠습니다. 배치 실행 시 Agent의 연동을 위해 자바실행옵션에 아래 내용을 추가합니다.
- javaagent : scouter agent lib 경로명
- Dobj_name=payJob : 오브젝트 이름 (클라이언트에서 보여지는 objName)
해당 배치를 실행하면 아래와 같이 Scouter와 모니터링 관련 로그가 나옵니다.
다운받은 Scouter 클라이언트를 콜렉터가 설치된 서버의 아이피/포트(127.0.0.1:6100)와 아이디/패스워드(admin/admin)를 입력합니다. 클라이언트를 띄워놓고 배치를 실행해보면 아래와 같은 프로파일링된 정보가 나타납니다.
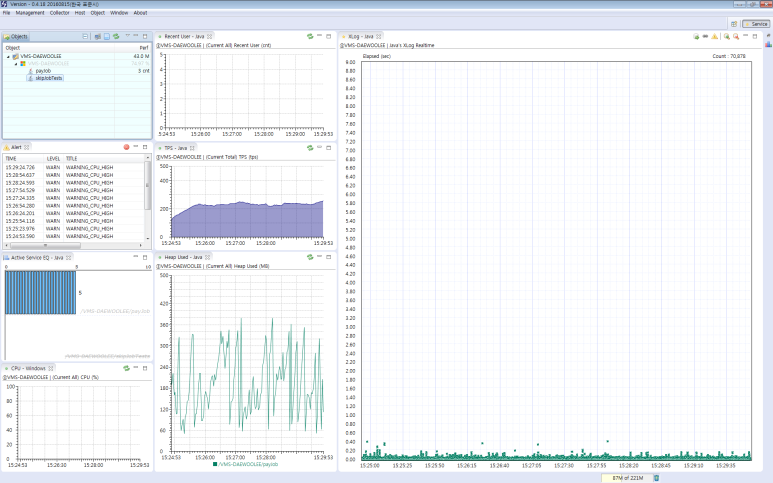
XLog-Java 뷰를 열어보면 각 서비스 단위의 프로파일링 된 정보를 확인할 수 있습니다.
- 쿼리 수행 시간 및 통계
- 서비스 요청 흐름 및 호출 시간 정보
- 서비스 수행 시간
- ..
배치는 5개의 쓰레드로 수행되고 있고 Active Service EQ에는 5개가 수행되고 있습니다.
이렇게 Scouter로 프로파일링 된 정보들은 실제 개발할 때에도 많은 도움이 됩니다.
예를 들면, 배치는 스프링 배치 Partitioner의 특정 쓰레드에서 에러가 나더라도 나머지 쓰레드가 다 수행될 때까지 진행되기 때문에 에러가 난 상황을 바로 캐치하기 힘든 부분이 있는데, Scouter로 저장된 XLog에 에러내용이 남아있기 때문에 디버깅이 가능합니다. 이외에도 수행시간이 측정되기 때문에 각 구간별 튜닝요소(SQL등)를 점검해 볼 수 있습니다.
Agent Plugin Script 작성
지금까지는 Scouter에서 제공하는 기본 프로파일링 정보만 클라이언트를 이용해 확인했는데요.
서두에 밝힌 바와 같이 각 서비스 별로 생성되는 데이터 및 프로파일링 된 일부 정보를 Agent 스크립트로 작성하여 프로파일에 반영해보겠습니다.
[순서]
1. Agent Plugin Script에서 Capture 플러그인을 이용해 해당 서비스 종료 시점의 return 값을
Desc Set한다.
2. 클라이언트에서 Desc 프로파일링 정보를 확인해보고 추후 서버 플러그인에서 활용한다.
스크립트 플러그인 자세한 관련 API 정보는 Scripting plugin java agent API 설명 페이지에서 참고하세요.
먼저 capture.plug 파일을 scouter.agent\scouter\agent.java\plugin에 생성합니다.
서비스 추적 종료 시점의 리턴 값을 가져오고 리턴 오브젝트를 스트링으로 변환하여 Desc에 Set하는 스크립트입니다.
저는 추적 서비스 종료 시점에 해당 플러그인을 사용할 계획이기 때문에 agent의 scout.conf에 hook_return_patterns 설정합니다.
설정 후 해당 배치를 실행하게 되는 아래와 같이 플러그인이 로드 되는 것을 로그를 통해 확인 가능합니다.
만일 capture.plug 문법 오류가 발생하면 아래와 같은 로그 메세지가 나타납니다.
배치 실행 후 스카우트 클라이언트를 확인을 해보면 아래와 같이 클라이언트 화면의 XLog에서 추적서비스의 리턴값이 desc에 세팅 된 것을 확인할 수 있습니다.

Agent Scripting Plugin은 코드 변경이 동적으로 로드 및 컴파일되어 런타임에 즉시 반영되므로 실시간 서비스에서 어플리케이션의 수정 및 배포 없이 디버깅 등에도 활용도가 높습니다.
Server Plugin 개발
서버 플러그인은 Script 플러그인과 Built 플러그인이 있습니다.
여기서는 Built-in Plugin을 특정방식으로 미리 제작한 후 아래 데이터를 Elasticsearch에 저장해보겠습니다.
[Elasticsearch에 저장할 데이터]
- Agent Script에서 세팅한 각 추적서비스의 리턴오브젝트의 desc데이터
- XLog 성능데이터 (service, error, elapsed등)
서버 플러그인에 대한 자세한 내용은 Plugin-Guide_kr 문서 참고하면 됩니다.
Elasticsearch 색인 구조는 상품ID, Service, Return Object, error, elapsed 등으로 구성되며 데이터는 추후 특정상품ID에 대하여 모니터링 데이터로 활용할 수 있는 구조로 만듭니다.
결국은 특정 상품ID에 대하여 정산에 필요한 판매데이터, 정산데이터를 각 서비스의 리턴값으로 확인하고 XLog 성능데이터를 모니터링 정보로 활용하고자 함입니다.
테스트를 위해 scouter-plugin-server-null 플러그인 프로젝트를 그대로 사용하였습니다.
XLogPack를 이용하여 아래와 같이 구현합니다.
구현된 서버 플러그인 프로젝트 빌드 후 Jar파일을 server/lib폴더에 위치 시킵니다. 그리고 Server를 재시작하면 아래와 같이 서버로그에서 Built-In이 올라간 로그를 확인하실 수 있습니다. (Script 플러그인과는 달리 재구동을 해야 합니다.)
마치며
이제까지 [Scouter설치 설정 -> 배치서비스의 서비스추적을 통한 프로파일링 정보 수집 -> Agent Plugin Script를 작성하여 프로파일링 정보 수집 -> 제작된 Server 플러그인 제작하여 XLog 및 Agent로 수집된 정보를 Elasticsearch에 저장] 해보았는데요.
물론 Scouter를 이용하지 않더라도 성능 관련 데이터를 수집할 방법은 많이 있지만, 성능 관련 데이터 개발 및 어플리케이션 수정을 하거나, 별도의 로그를 만들고 해당 로그를 수집하는 별도의 집계 시스템을 만들어야 하는 비용이 발생합니다.
이런 관점에서 본다면 Scouter가 제공하는 일부 설정만으로도 다양한 프로파일링 정보들을 그대로 활용할 수 있고, 어플리케이션 수정 없이 별도 플러그인 개발으로 집계시스템을 만드는 점은 매력적으로 보입니다.
이외에도 XLog의 데이터를 이용하여 특정 상황 발생 시 Alert 기능을 활용한다면, 다양한 채널(메일/SMS/메신저 등)로 인지가 가능해 빠른 대응으로 안정적인 서비스를 유지할 수 있습니다.
Open source APM Scouter로 모니터링 잘 하기 슬라이드의 문구 중에 아래와 같은 문구가 나오는데요.
문제의 식별 - 어플리케이션 모니터링
문제의 해결 – 어플리케이션 튜닝
▶몰라도 보이고◀ 보이는 만큼 개선할 수 있다.
오픈소스 APM Scouter는 좋은 선택이 될 수 있습니다.
[출처] 배치 모니터링, Scouter로 편하고 효율적으로!|작성자 개발몬스터