검색엔진(Search Engine)의 현황 및 구동원리
1. 국내의 검색엔진
검색엔진 전문가로서, 많은 분들이 검색엔진하면 어렵다는 편견을 갖는 분들이 많다. DB는 스페셜하게 잘 다루지만, 검색엔진은 왠지 전문가만 다뤄야 할 것만 같아서 검색엔진을 사용하면 훨씬 효율성이 높은 부분 마저도 DB에서 Like 쿼리를 사용하는 사이트가 허다하다.
그렇다고, 국내의 검색엔진 업체 제품을 쓰면 왠지 손해보는 느낌이 강한데... 왠만한 검색엔진 값이 차 한대값과 맞먹고, 라이센스에 따라서 아반테가격에서 벤츠가격까지 올라가는 경우가 존재한다.
국내의 검색엔진 업체는 와이즈넛, 코난테크놀로지, 솔트룩스의 3파전 양상이다. 이중 와이즈넛이 가장 유명하지만, 그렇다고 기술력이 가장 뛰어난 업체는 아니다. 와이즈넛과 코난테크놀로지는 검색엔진 순수 기술로만 하면 BMT 스코어가 오히려 코난테크놀로지가 높은 경우가 많이 발생하나 최종 가격이나 종합적인 스코어로 와이즈넛이 수주가 잘 되는 경우가 많고, 오히려 검색엔진 이외의 솔루션에서 와이즈넛이 잘 되어 있다고 생각한다.

검색엔진의 3대 솔루션 업체인 와이즈넛(Wisenut), 코난테크놀로지(Konantechnology), 솔트룩스(Saltlux)
솔트룩스는 빅데이터 및 인공지능의 시장이 되면서, 최근 가장 핫하게 뜨고 있는 업체인데 사실 엄청난 기술을 보유한 것같아 보이지만 실상 까놓고 보자면 오픈소스를 덕지덕지 활용하여 만든 솔루션이고, 타 기업과 별반 다를바 없다.(예전에는 솔트룩스의 화려한 언변에 많은 기업들이 프로젝트를 맡겼다가 윈백 당한 사례가 많았다) 국내 솔루션 업체들의 한계인데 사실 오픈소스를 불안해하면서 싫어하는 수많은 높은 결정권자가 아니었으면, 국내의 솔루션 업체들은 사실 발조차도 올리기 힘들었을 것이다. 그러나, 다시 까보면 그 국내의 솔루션 제품들은 코어는 아니겠지만 오픈소스가 덕지덕지 붙어있는 경우가 많다는 것이 함정이다.
2. 오픈소스 검색엔진
저 3곳의 업체들은 국내의 SI의 발을 오래 담근 분들은 거의 아는 업체겠지만, 검색엔진을 이제 막 배울려는 사람에게는 저게 뭐하는 업체인가 할 것이다. 사실 대부분은 루씬(Lucene), 솔라(Solar), 엘라스틱서치(Elasticsearch) 정도만 알지 검색엔진 업체명을 모르는 건 당연할 것이다. 루씬, 솔라, 엘라스틱서치는 사실 하나의 몸에서 확장된 부모와 자식같은 존재들이다. 루씬이라는 부모에게서 솔라와 엘라스틱서치라는 자식이 태어났는데 솔라와 루씬은 같이 살고 있고(같은 프로젝트), 엘라스틱 서치는 처음부터 아내를 위한 어느 로맨티스트의 개발자한테서 만들어진 프로그램인데 수많은 개발자들과 협업하면서 계속 버전을 확장해 나가고 있다.

루씬, 솔라, 엘라스틱서치는 사실 한몸과도 다를바 없다.
그럼 왜 루씬 기반으로만 만들어지는 것일까? 검색엔진이라 하면, 사실 3가지의 기능을 가지고 있어야 하는데 하나는 형태소 분석기와 색인(Index)을 하는 기능, 마지막으로 검색을 하는 기능이라고 보면 될 것이다. 누가 나보고 자바로 검색엔진을 정말 간단하게 짤 수 있겠냐고 물어본다면, 나는 하루면 짤 수 있다고 말할 것이다.
검색엔진을 정말 간단하게 프로토타입 형태로 만드는 데에는 사실 하루도 걸리지 않는다. 얼마전에 프로토타입으로 분석 데이터를 화면에 노출하기 위해서 간단히 구현한 적이 있는데 반나절만에 만든 기억이 있을 정도니깐...
그만큼 어찌보면 구조는 매우 명확하고, 어렵지 않을 수 있으나 파고 파면 끝도 없는 것이 사실 검색엔진 솔루션이다. 그 어느 솔루션이 안 그러냐? 라고 반문할 수 있지만, 검색엔진 만큼은 절대 혼자서 제대로 만들 수는 없다. 그 이유는 3가지의 기능 중, 색인을 생성하는 프로그램은 어느정도의 숙련된 개발자라면 충분히 개발이 가능할 것이나, 형태소 분석기는 완전 다른 이야기이기 때문이다.
우리나라의 말들의 패턴을 거의 모두 가지고 있어야 하며, 수많은 단어 사전을 기본적으로 가지고 있어야 한다. 이 단어가 명사인지 동사인지 혹은 복합명사인지 등을 알아야 하는데 이런 기능은 단순히 개발자가 만들수가 없다. 전문적으로 국내의 형태소를 전문적으로 배운 사람과의 Co-work이 없으면 만들수가 없는데 그래서인지 검색엔진은 유독 오픈소스가 수가 부족하며(사실 루씬이 매우 훌륭하다) 엄두도 못내는 경우가 많다.
3. 검색엔진의 구동원리
위에서 적은 것처럼 검색엔진은 3가지의 기능을 필수로 가지고 있어야 하는데 그 중 가장 어려운 것이 바로 형태소 분석기라고 볼 수 있다. 색인과 검색 관련해서는 개발자라면 어느정도의 시간이 주어진다면 개발이 가능하나 형태소 분석기는 견적이 잘 나오지 않는다. 물론 ROI를 중심으로 해야 한다면, 오픈되어 있는 사전과 패턴을 가지고 만들겠지만 오픈소스 형태소 분석기는 루씬처럼 훌륭한 속도를 내지 않는 경우가 허다하고, 그렇다고 속도를 높이면, 제대로된 형태소를 추출하지 못하는 경우가 발생한다.
아래는 형태소 분석기 왜 어려운지 사례를 적어보도록 하겠다.
저는 자바개발자입니다.
아버지가 방에 들어가신다.
아버지 가방에 들어가신다.
Twice를 보니깐 심쿵 될 뻔 했어요.
첫번째는 복합 명사의 사례이다. 사실 "자바개발자"라는 단어는 사전에 존재하지 않는다. 저는 ~ 입니다 라는 패턴안에 있는 단어를 하나의 "명사"로 뽑았다고 했을 때, "자바개발자"를 하나의 단어로 인식시키면, 저 문장은 자바로 검색이 되지 않는다.
즉 "저는 자바개발자입니다"는 "자바, 개발자"로 분리되어서 뽑혀야 한다. 물론, 레벨을 좀 더 높혀서 "자바,개발자,자바개발자"까지 뽑는 것이 일반적이다.
두번째와 세번째는 흔히 말하는 사례중 하나이다. 형태소를 분석하는 가장 쉬운 방법은 모든 공백을 제거하고, 단어사전을 Loop 돌리면서, 해당 단어가 있는지의 여부를 찾는 것이다. 그렇다면 두번째와 세번째는 동일하게 뽑혀 버리는 사태가 발생한다.
마지막 Twice를 보니깐 심쿵 될 뻔 했어요. 라는 문장인데 Twice는 단어사전에 존재하는 단어기 때문에 문제 될 것이 없지만, "심쿵"이라는 신조어는 어떻게 인식을 할 것인지도 중요하다.
결국, 형태소 분석기는 기술과 시간과의 싸움이다. 시간을 들여서 사전을 구축한다하더라도, 그 수많은 사전을 Loop 돌릴 것인가?? 만약 200만개의 사전이 존재한다면, 단어별로 다 루프 돌려서 문장을 찾는다?? 그런식으로 형태소를 분석한다면, 끝도 없이 돌아갈 것이다. 그렇다고 사전이 존재하지 않으면 정확성이 떨어질 것이다. 이를 해결하기 위한 기술력 역시 필요한 것이다.
나. 색인(Index)
형태소 분석기도 매우 중요하지만, 색인을 하는 것 역시 중요하다. 형태소 분석기를 돌린 결과를 토대로 데이터를 빠르게 찾기 위해서는 색인이라는 것을 활용해야 하는데 색인을 쓰지 않으면, 모든 데이터를 일일히 찾는 멍청한 엔진이 될 것이다.
일반적으로 색인은 단어와 레코드 주소를 Key, Value로 묶어서 저장하는 구조를 가진다. 이를 역 색인(Inverted Indexing)이라고 부른다. 예를 들어, 문서가 수백만건이 존재한다고 해보자. 그런데 "엘라스틱서치"라는 문서가 그 중 10개밖에 안된다고 가정해보자.
하나씩 하나씩 DB로 말하자면, Full Scan하는 것보다 아래와 같은 구조를 가지면 데이터를 매우 빠르게 찾을 것이다.
엘라스틱서치 = 101001, 101002, 101010, 100101 .... 397812
위와 같은 구조로, 키, 밸류로 저장을 한다면 우리는 엘라스틱서치 안에 있는 해당 문서만 가져와서 사용자에게 보여주면 될 것이다.
다. 검색(Search)
검색엔진을 설명하는데 검색이 없으면, 말이 안되는 것처럼 당연히 검색기능이 얼만큼 중요한지는 말을 안 적어도 다들 잘 알 것이다. 사실 형태소 분석기나 색인 기능은 없어도 돌아갈 순 있다(데이터가 매우 적다면, Like 등을 쓰면 되니깐...) 하지만, 검색 기능이 없다면 검색엔진이라는 말조차 쓸 수 없다는 것은 너무나도 당연한 말일 것이다.
검색은 사용자의 질의(Query)를 분석하여 원하는 결과를 찾아주는 데 여기서 형태소 분석기를 마찬가지로 활용하게 된다.
4. 검색엔진의 구성도
위 내용을 구성도로 그리면 아래와 같은 어찌보면 간단한 형태의 구조로 보일 순 있다.
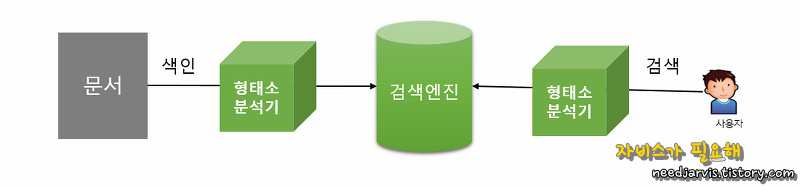
그림은 간단하게 보일 순 있지만 내부의 로직들이 매우 복잡하고, 형태소 분석기는 사전을 품고 있으며, 문서, 로그 혹은 DB를 가져오는 프로그램(Connector or Crawler)도 필요하다. 위와 같은 구조는 모든 검색엔진이 동일하게 품고 있는 구조라고 보면 되기에 추후 엘라스틱서치를 실습하면서, 보충 설명을 할 예정이다.
출처: http://needjarvis.tistory.com/167 [자비스가 필요해]